
The Bikini Bottom Marathon
What is caching?
Caching is the practice of storing something in a location from which it can be quickly retrieved, thereby speeding up future accesses. It's not always permanent--it's more of a short-term memory for whatever you might need really soon. Think of an in-process cache as your short-term memory and a more robust, distributed cache as the memory you share across a team or a global network.
Let us visit a real-world example: a conversation with Patrick Star.
Newcomer: "Hi, my name is Patrick." You: "Hi, my name is-" Patrick: "Hi, my name is Patrick."
You are astonished. Why is his name so important to him that he interrupts your introduction? You try again:
You: "Hi Patrick. My name is-" Patrick: "Hi, my name is Patrick."
You leave, exasperated, but you can't shake his name from your head. Eventually, after enough time and other things on your mind, you might forget it. But for a while, it was easily retrievable. Essentially, your brain cached the name "Patrick" for quick access.
This, my friend, is not a lesson on neuroscience, but an illustration of the essence of caching--storing data for quick retrieval.
Why not start with the big guns?
You might be tempted to jump straight to a distributed caching solution with multiple nodes spanning continents. As fair as that is, I don't think that I would build a ten-story skyscraper to house my two-person lemonade stand. I don't want to incur the complexity and overhead of a ten-story skyscraper until I need--potentially have a use for it (whoops, I caught myself there). Remember, we don't necessarily need to use something. There is most likely an alternative that has trade-offs. As you build your skyscraper certain decisions become more niche. Remember that--both in system design and in life. Oftentimes, there isn't a right or wrong, but possibly a solution that serves you all the more.
Now, caching can start small and evolve:
- In-Process Cache: Keep data in the same memory space as the application.
- Single Node Cache Server: Offload caching to a dedicated server (e.g., Redis on one instance).
- Clustered/Partitioned Cache: Scale out to multiple nodes and possibly shard data.
- Geo-Distributed Caching: Multiple cache clusters in different regions to provide low latency globally.
Let's explore each step in more detail.
1. In-Process Cache
What it is
An in-process cache is data stored within your application's memory space. Every time you need quick access to certain results--like a list of trending products or the last few queries executed--you keep them in RAM (Random Access Memory) right alongside the code.
When to use it
- Early-stage projects with minimal concurrency.
- Microservices that benefit from ephemeral caches for quick lookups.
- Prototypes where you just need a simple performance boost.
Example
Imagine you have a Python function that calculates Fibonacci numbers, a notoriously expensive operation for larger inputs. You can create a basic Least Recently Used (LRU) cache:
from itertools import lru_cache
@lru_cache(maxsize=256)
def fib(n):
if n <= 1:
return n
return fib(n-1) + fib(n-2)
# Usage
print(fib(10)) # Cached calls, much faster on repeated calls
All it does is keep recently used results in RAM. No network overhead, no extra servers. Easy!
Limitations
- Memory constraints: You're limited by the memory of your application instance.
- Scalability: If you scale horizontally (multiple app servers), each instance has its own cache--no shared state.
- Process restarts: If your service restarts, the cache is gone!
What we have learned so far
Okay, so an in-process cache is data stored in the same server, hugging the code that you just wrote (like a side hug). So, if you need to get that same data, depending on our needs (LRU only describes the least recently used cache, as there are many more), it comes much faster. We can couple this cache mainly with low-resource projects and applications.
Everything comes with a trade-off, and what we get here are scalability and fault limitations. When we run out of memory, usually a cache just throws a lot of its stored data away to make up space (how convenient). If we started getting more traffic and add some servers to handle the new load, each instance of the app will have its own cache--no shared state (oh, but what if we wanted trending products for all users...). And last but not least, if our service restarts (oop-, maybe it crashed due to load), the stuff we had in that cache is... gone! What can we do to handle these limitations?
2. Single Node Cache Server
What it is
You're running a race and your friend Patrick Star decides to join you. But he does something quite odd. He jumps on your back so you can carry him to the end of the race! You try your best--you've been training for this race all your life, but not with an oversized (seriously, how did he get as big as a human) starfish strapped to your back! You're quick-witted and share Patrick your plan: for him to run alongside you/to run his own race, just with a walkie-talkie strapped to him... just in case he manages to fall behind (amongst other things). He agrees. A relief, for now.
Rather than storing cached data inside your app, you run a separate cache server (e.g., Redis, Memcached, Hazelcast). Your application connects to this server over a network.
When to use it
- Multiple application servers need to share the same cache. Our last situation, we were limited by: memory (ugh, we can only use the memory we have from our current app server), scalability (we added app servers later on to help with load and our cache was not sharing data), and fault tolerance (our service would restart, and now our fast data retrieval is no more).
- You want to avoid replicating large data sets in each server's in-memory cache.
- You need persistence (some caching servers provide configurations to save data to disk).
How it works
- Your app receives a request, checks the cache server for data.
- If we find it (cache hit), return immediately.
- If we don't (cache miss), compute/fetch from DB, then store in the cache for next time.
# Install Redis (e.g., on Ubuntu)
sudo apt-get update
sudo apt-get install redis-server
# Run Redis
redis-server
import redis
r = redis.Redis(host='localhost', port=6379, db=0)
def get_user_profile(user_id):
...
# Check cache First
profile = r.get(f"user:{user_id}:profile")
if profile:
return profile
# Not in cache? Fetch from db
profile = db.execute("SELECT user_id, full_name, hobbies FROM users")
results = db.fetchall()
db.close()
# Store in cache with an expiration of 60 seconds
r.setex(f"user:{user_id}:profile", 60, profile)
return profile
print(get_user_profile("123"))
Limitations
- Single point of failure: If the cache server fails, your entire cache is gone.
- Limited scale: Eventually, one server might not handle the volume of queries or size of cached data.
- Network overhead: Accessing the cache over the network adds latency, albeit minimal compared to its reduction of overall latency.
What we have learned so far
We were doing great until we weren't. But isn't that also great? People are using the thing we built. Now we have to handle this new amount of load and want to share cached data amongst these new servers.
Enter the single node cache server. We separate Patrick Star from us so we can run well, and, hopefully, he can keep up the pace. This is us creating a separate cache server for our cache to run on. When someone asks us how we're doing, Patrick, if I just recently told him (depending on what we've decided he remembers), may answer for me. I hope he has the answer, because that'd save me a lot of breath so I can focus on running my race. If not, I can either tell them myself or tell Patrick first over the walkie-talkie (ultimately, I should let Patrick know what I need him to remember for next time).
Oof, enter some problems with our plan (since no plan is perfect). If Patrick falls, there will be a period of time where I will need to answer questions instead of them going to Patrick. He can't even answer while he's on the ground, so we take on all the load he was "off-loading". 5 minutes pass and Patrick gets back up. But now, oof-- there's a lot of new questions he's getting asked... sometimes they are long, and sometimes there are way too many. He starts getting a headache and lets us know that he needs to take out some of the answers he's remembered since it's hurting his brain. Yikes... Is there any way we can handle problems like these?
3. Cache Clustering/Partitioning
What it is
Suddenly, Sandy Cheeks and Squidward Tentacles (yes, you heard right) come out of the blue with walkie-talkies in hand, ready to do Patrick's job! They're all running together and decide that each will hold the answer to some of the questions (not just randomly picked, of course). WAIT! Spongebob comes out of the blue (I bet you thought you were Spongebob at this point) and REPLICATES HIMSELF so that each set of answers can have replicas. Because... what if Patrick falls again? Then a Sponge clone (that's what I call them) will take his place!
In other words: clustered or partitioned caching is where you have multiple cache servers working in tandem to store data. Each server may hold a portion of the data (sharding) or replicate data among peers for fault tolerance.
When to use it
- High throughput: You're serving tens of thousands (or millions) of requests per second, and one cache server is a bottleneck.
- Large data set: The total cached data exceeds what one server can store in memory.
- High availability: You want some nodes to keep serving requests if one node fails.
Approaches
- Sharding: Distribute keys across multiple servers using a consistent hashing strategy. We can do so by creating virtual nodes based on a hash function per server and allocated "nodes" and add whatever we need to these nodes from the hashing of the keys, so as to keep related keys near each other.
- Replication: Keep copies of data across multiple servers for fault tolerance. There are different ways caches and DBs can do this based on the need of the system.
- Combination: Shard first, then replicate within each shard group. This is a good one.
Example: Redis Cluster
- Redis Cluster automatically shards data across multiple nodes and can replicate shards for high availability.
- Client libraries understand how to connect to the cluster and find the correct node for a given key.
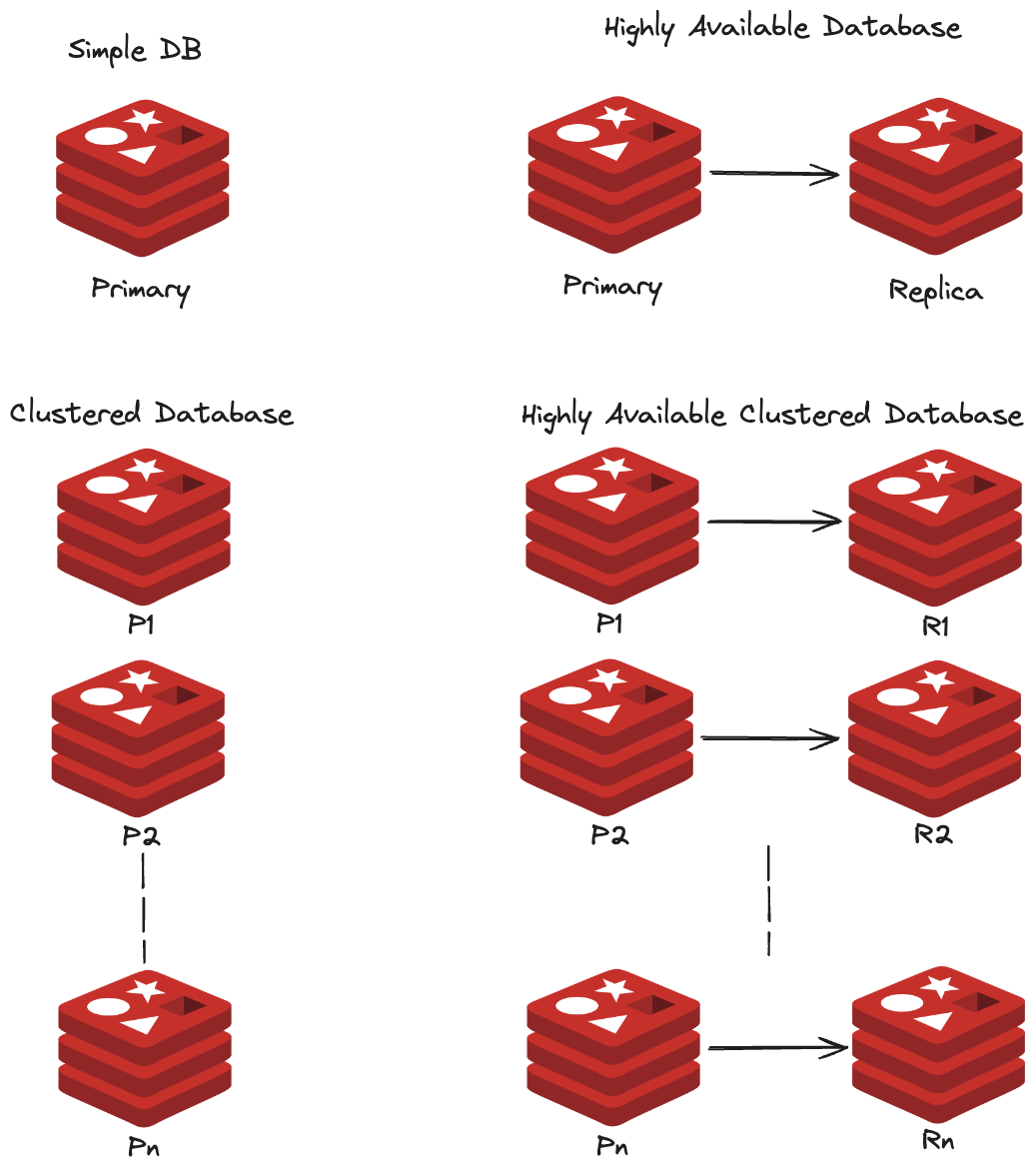
Redis high-availability data architecture diagram
Limitations
- Operational complexity: It's tricky. Managing multiple nodes, consistent hashing, and replication? Oof--make sure you have people who can run that well.
- Data consistency: In distributed scenarios, sometimes data may be stale or out-of-sync momentarily.
- Cost: More servers = higher costs in infrastructure and maintenance.
What we've learned so far
We added some great teammates to help us manage our load. We even have sponge clones (who would've thought)! We identified that we needed something that can handle a lot of chatter from these folks not running (hmph) and different types of chatter. We even made sure that if Sandy, Squidward, Spongebob, or Patrick need some water or end up out-of-commission for a bit, we've got backups! We can handle higher throughput, can store more cached data, and increased our availability. That is amazing.
We used sharding to distribute data to different servers and caches, keeping similar data close to each other. We also replicated that data, keeping copies of each shard across multiple servers. But... but... this is kinda hard. Keeping everything going, in-sync--even managing the clones! And what if Sandy didn't tell one of her Sponge clones something she knows before she stepped out for some water? Not only that, we had to pay for each person to be in the race. And that doesn't even account for how the audience is supposed to know who to talk to first to answer their question. But, have no fear, there is a solution to every problem. Although, what I'll talk about next doesn't necessarily answer it.
4. Geo-Distributed Caching
What it is
Imagine our race takes place across multiple cities or even continents—and we have different teams of Patricks, Sandys, Squidwards, and Sponge clones in each location to answer questions from the local spectators. Each local cluster can store and serve data for its own region, minimizing the distance (network latency) that queries have to travel. That is geo-distributed caching in a nutshell: multiple cache clusters in different geographic areas, each serving local traffic.
When to use it
- Global user base: You have customers around the world who need low-latency access to data.
- Super high-availability: If one entire region goes down (or gets blocked, or experiences a natural disaster), other regions can still serve.
- Multi-region architecture: Data is replicated so each region's cache can serve local reads quickly without hopping across the ocean to fetch data.
Approaches
- Regional clusters: Each region runs its own cache cluster. Requests from that region are automatically routed to the nearest cluster.
- Global invalidation: Changes in one region can be replicated or invalidated in other regions if keeping them in sync is crucial.
- Eventual consistency: Often, caches can be slightly behind the "sources of truth" if real-time global sync isn't required.
Limitations
- Complexity: Coordinating data updates or invalidations across regions is tricky.
- Cost: Operating multiple clusters worldwide can get expensive--think infrastructure, personnel, and data transfer costs.
- Latency for invalidation: Syncing changes across continents can introduce slight delays, so apps must tolerate eventual consistency.
What we've learned so far
If you have fans all over the globe asking "What's the name of that starfish running the race?" you don't want them all calling a single phone line in Bikini Bottom--lines get jammed! Instead, station local "cache servers" in each continent who have the answer, so the questioner in Asia doesn't have to wait for a response from the US. Of course, if Patrick changes his name (to "RickPat" maybe?), you'll need a way to quickly tell every local cache, "Hey, flush that old name. Here's the new one." That's the challenge of geo-distributed caching.
Putting it all together
The caching evolution
- In-process cache
- Perfect for simple, low-scale scenarios.
- Lives and dies with your application process.
- Single node cache server
- Centralized, easier to share across multiple app servers.
- Beware of single point of failure.
- Clustered/partitioned cache
- Horizontal scalability and better fault tolerance.
- More nodes = more complexity in setup and maintenance.
- Geo-distributed caching
- Minimizes global latency; high availability across regions.
- Orchestration, data consistency, and cost can be significant.
Closing thoughts
Caching is the short-term memory of your system--fast, convenient, and cost-effective (when used wisely). You don't start with a ten-story building when a tool shed might do. The same logic applies to caching strategies: pick the simplest possible design that meets your current needs, and only scale out when those needs inevitably grow.
- If you're just beginning, in-process caching offers a quick win.
- When you need multiple servers to share data or want persistence, add a single node cache server like Redis.
- If traffic and data outgrow that setup, embrace cache clustering to handle higher throughput.
- Finally, if you serve global audiences, geo-distributed caching ensures snappy response times and continued access even if one region is down.
Remember, each step up the caching ladder introduces extra complexity, cost, and operational overhead. So take it one stride at a time--just like Patrick, Sandy, Squidward, and the Sponge clones in the big race!
If you find yourself confused along the way, just remember the name you cached earlier: "Patrick Star". Because in caching, some things are just worth remembering.